实验目的
比较三种Attention机制在机器翻译任务上的表现。分别为:Bahdanau Attention(D. Bahdanau et al. ,2015),Convolutional Attention(Jonas Gehring et al. , 2017),以及基于Self Attention机制的Transformer(Vaswani et al. ,2017)。
| model | Bahdanau Attention | Convolutional Attention | Transformer |
|---|---|---|---|
| base model | Alignment Attention | Alignment Attention | Self Attention |
| encode cell | RNN | CNN | Linear Layer |
实验环境
Bahdanau Attention测试于系统1
Convolutional Attention测试于系统1、2
Transformer (1 Layer, Hidden Dim 256)测试于系统1
Transformer (6 Layer, Hidden Dim 512)测试于系统2、3
| 系统1 | 系统2 | 系统3 | |
|---|---|---|---|
| Operating System | Windows 10 Professional | Ubuntu 16.04 | Ubuntu 16.04 |
| Torch Version | 0.4.1 | 1.2.0 | 1.2.0 |
| CPU | Intel i7 6700HQ | AMD Ryzen5 2600 | Intel Xeon E5 2600 |
| GPU | Nvidia GTX 960M | Nvidia GTX 1070 | Nvidia Tesla K80 |
| GRAM | 4 GB | 8 GB | 24 GB |
| RAM | 16 GB | 16GB | 160 GB |
实验过程
数据
数据集加载自WMT16 DE-EN翻译数据集中的一部分。使用torchtext加载并预处理数据集,使用SpaCy分词,同时使用torchtext.Field对象构建源语言与目标语言的词表,并筛去词频为1的罕见词。最终使用torchtext.BucketIterater构造训练集与验证集的迭代器。
模型
本次实验所使用的模型均基于Seq2Seq结构,具有一个编码器(encoder)以及一个解码器(decoder)。编码器负责捕捉源语句的分布式语言信息,而解码器在训练时使用翻译后的gold sentence监督。具体方法是在句子之前加入一个标志词”SOS“表示句子的开始,而解码的句子则应该是在gold sentence后添加一个结束符”EOS“结束翻译。最后将解码结果的除去最后一个字符与Gold Sentence的每个词做交叉熵损失即可完成一句话的训练。
而Seq2Seq的RNN Baseline就是先使用一个RNN网络,将每个源语言句子的单词的词嵌入均送入网络,然后将最后一个时间步的隐藏态tensor作为这个源语言句子的唯一表示(或者使用max pooling或average pooling等方法凑出一个源语言句子级别的表示)。最后将这个隐向量作为解码器的初始隐藏状态,剩下的过程就是将目标句加上SOS输入decoder即可。
因此在这里很显然有一个问题,因为RNN是时序敏感的,最后一个状态的hidden tensor往往更加依赖于最后几个时间步的输入,也就是可能最后表示的只是句子的后半段。而对于句子的其他部分而言,这种有偏向性的表示很显然是没有多少信息增益的。因此一种小小的该进就是将训练的时候的语序反转过来,从最后一个词预测,这样的话可以有效利用之前encoder返回的表示太过偏后的信息,然后在由后向前翻译的时候,decoder也许会自动捕获出一种语言模型成功推导出之前的表示。但是这依旧是一种治标不治本的改进。即使是诞生之初就为了解决RNN网络梯度问题的基于门控机制的LSTM于GRU也不能很好地解决这个问题。
因此Attention机制的诞生之初的目标就是为了能通过一种网络结构,学习出各个时间步,也就是对于各个单词而言,到底哪些信息是对它有用处的。对于机器翻译而言,自然是寻找译文中的每个词于原文各个部分的相关度,也就是”对齐’’, 如果两个部分是语义上对齐的,那么就应该可以直接翻译过去,而其他不相干的部分就可以“不看”了。所以attention也可以理解为隐向量间的一种隐藏维度上的数据库,通过隐藏维度作为中介的转换,则得到了给定查询向量(即当前状态),返回原文的加权表示的一种机制。
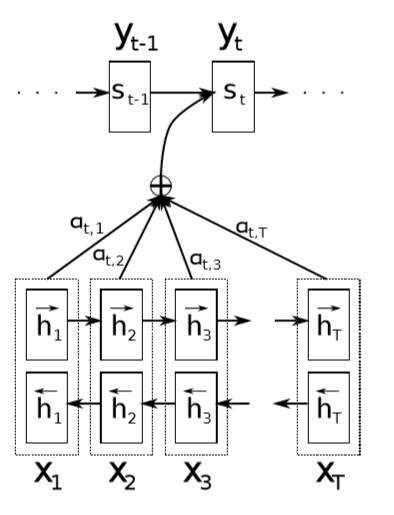
Bahdanau Attention
由D. Bahdanau et al.于2015年提出的基于循环随机网络的模型。核心思想是基于传统的RNN-Base的attention机制,但是再加上一个线性变换为主的attention层,负责在解码器的每个时刻,根据解码器此时的状态(此时解码器RNN上一个时间步$t-1$的$hidden$, Encoder传回的整个源语言句子的表示$h_{enc}$,此时输入的单词的词向量$v_t$等等),从而建立一个查询的矩阵,根据此时的综合状态(一个hidden tensor)查询这个tensor在encoder各个时间状态上的一个概率分布,最后将得到的attention分数也就是分布与encoder的全部输出(也就是每个时间步的一种表示)做加权和得到的当前状态所关注的一种句子表示,将这个于词向量做一个拼接得到当前的一个全部状态,然后放进decoder解码。其余部分与RNN Baseline一样。
Convolutioal Attention
在这里attention机制的思路与Bahdanau Attention的思路如出一辙,但是在编码器和解码器上则是基于CNN的。
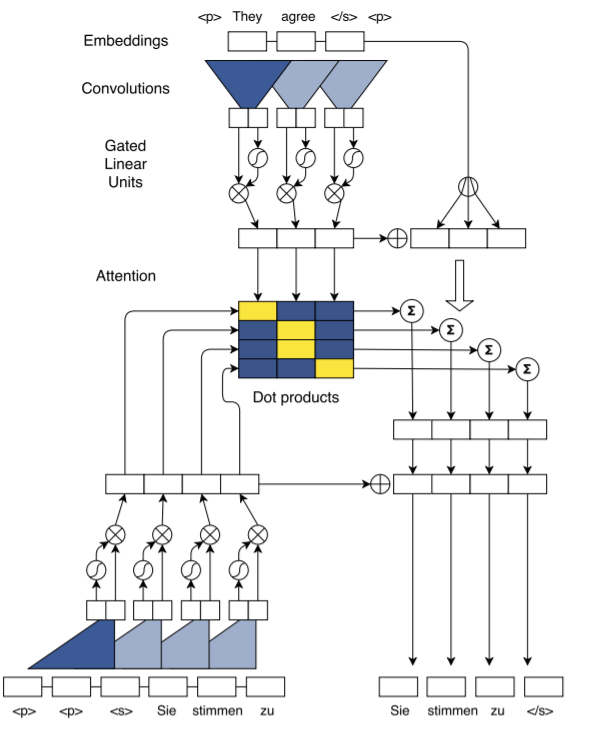
在实现中还使用了位置的Embedding,因此弥补了CNN没有捕获时间信息的能力,这对于NLP任务十分有效。在这里我是用了一个位置编码,使用一个embedding层讲相对位置送入即可,然后拼入词嵌入空间。接着用卷积核大小为3的CNN捕获句子的结合周围词的一种表示,在经过一个GLU层(类似GRU的门控机制)。这个层是为了作为网络的非线性部分增强表示能力。而在Encoder中的门控部分之后还可以增加一个残差连接(与GLU合起来就像Highway Network一样的结构)以扩充信息传播路径。
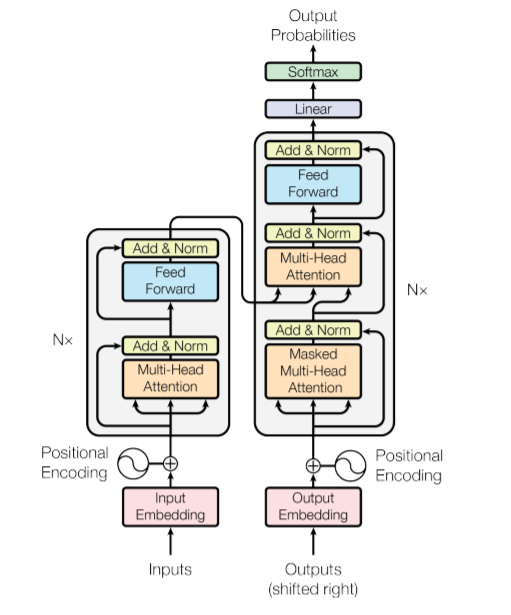
Transformer
与之前两个模型不同,transformer是一个基于self attention的模型。self attention的创新点是把attention的对象从之前encode的每个时间步的全部隐藏向量的表示中移开,完全抛弃这一隐藏表示,只用关注自己即可。
在Encoder中,self attention关注的是每个词自己和周围其他词之间的某种联系,提取的是源语言上每个单词的语境信息。而在decoder中,self attention也是先提取翻译后的语句中每个单词的语境信息。但是考虑到在翻译中,我们只能知道源语言句子的信息,以及自己已经翻译完的上文信息,故我们需要在decoder中增加一个上三角矩阵所为mask机制,这样就限制了decoder所能掌握的上下文信息。然后再映入源语言的Key与Value向量,然后将刚刚已经训练出的目标语言的Query向量直接进行查询,就自然得到了现在的单词结合了源语言上下文信息的一种表示,就自然地完成了自对齐。
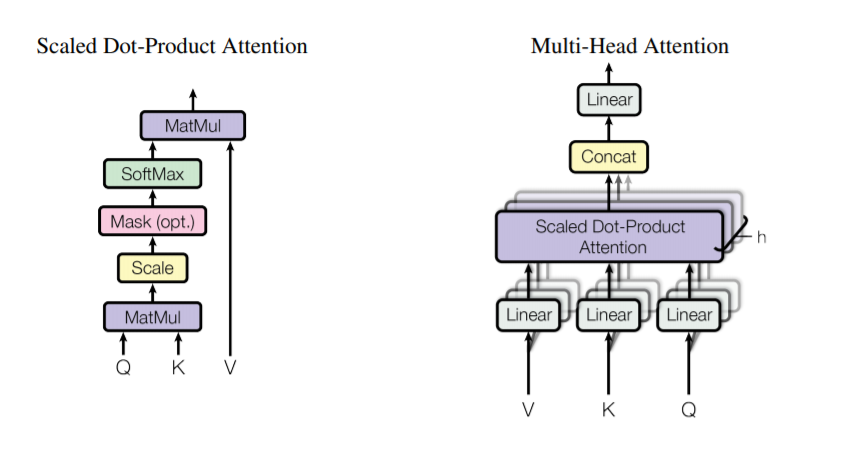
这里有三个tensor,$Q,K,V$。这三个向量分别是查询,键与值。这三个tensor其实与输入的词嵌入的维度一样,所以这也是Transformer可以以任意深度叠加的原因。因为每一个输出都是下一层的$Q,K,V$。
当$Q$与$K$相乘时,我们可以得到一个 (句子长度*句子长度) 的二维矩阵,这时再乘上键值$V$很自然地得到了当前句子结合自己而得到的一种新表示,encoder最后的输出无疑就是原句子的一种表示,会被作为每个Decoder层的键与值向量。就是因为字注意力,这些一个句子对应的这三个向量一定是相等的。值得注意的还有一个优化就是Scale因子,由于self attention是乘法attention与加法的传统attention不同,如果矩阵运算次数增多,那么矩阵中的方差就会被放大,因此缩放因子就是隐藏维度的平方根。当然论文指出对于较小的维度,不使用缩放不会造成说明性能损失。
由于为了增加更多语言信息的捕获,还会将词嵌入空间拆解为多个头,这样在每个transformer模块中,每个头就是负责其中一片维度的信息处理,输出时又会讲各个头拼接起来获得完整的向量。同时,层间都要增加一个残差连接,减小模型深度的需求。并且要做layer norm,防止某些维度的值特别大,影响其他注意力信息。
在最终得到表示之前,模型还有个position feedforward网络,这个网络是为了增加模型的非线性。因为整个模型都是基于自注意力,也就都是线性变换,但是很显然,一个任意层的线性神经网络其实等价于一个,所以这便会使得模型的表示空间变得很低。通过先将隐藏维度映射到4倍空间的线性层,然后再映射回去,并且在中间还要添加一个激活函数,这样就保证了模型的表示能力。
还有一个机制就是位置编码。论文中使用的不是Convolutional 模型使用的Embedding层输入index得到的位置嵌入向量,而是使用:
这样就可以直接计算出位置的表示而不需要去学习。这种机制的可行处可能是这样能表达句子位置的相对关系,因为这可以看作将绝对位置映射到三角函数的空间,基于和角公式和差角公式我们可以轻易的建立文本相对位置编码的运算,最关键的就是这样所有的维度的值域均在$[-1,1]$上,很适合神经网络的输入,非常巧妙。同时作者指出的是,由于位置的嵌入是与词嵌入一同进行线性变换得到的新表示,那么在传播梯度的时候很可能两者信息会在某些维度上混合。而硬编码不仅仅降低了计算量,还保证了性能,实验结果二者几乎一样。在我个人做的消融实验中,某些情况下,位置硬编码的模型性能甚至还更好(尽管2018年后的预训练模型又取消了位置预编码)。
实验结果
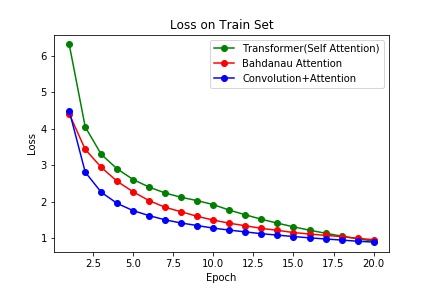
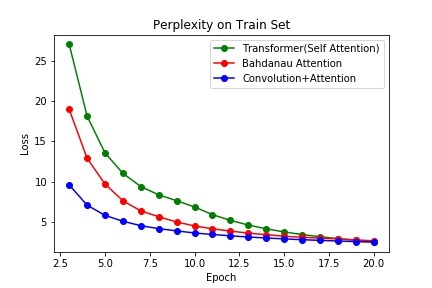
实验每个模型一共做了20个Epoch,没有使用early stopping。
-
batch大小: 128
-
梯度裁剪最大范数:1
-
优化器: Adam. 其中transformer的学习率使用了论文的公式:$lrate = d_{model}^{-0.5} min(step_num^{-0.5},step_num warmup_steps^{-1.5})$
-
Convolutional Attention中的卷积核大小均为3
Bahdanau Attention Conv Attention Transformer(self attention) Word Embedding Dimension 256 256 512 Number of Layers 4(bi-direction) 10 6 Hidden Dimention 512 512 None
The Best Model
| Bahdanau Attention | Conv Attention | Transformer(self attention) | |
|---|---|---|---|
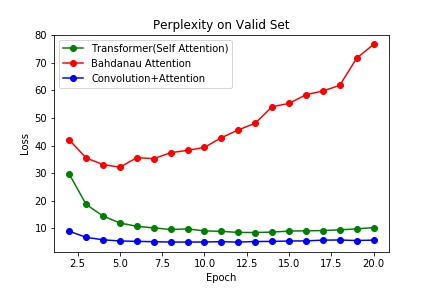
| Best Perplexity on Valid | 32.14530055920051 | 4.96706336493209 | 8.427502524306005 |
| Epoch Achieved | 5 | 9 | 12 |
实验总结
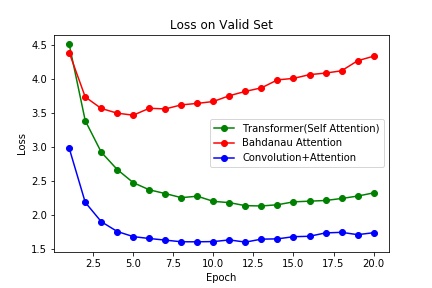
在基于WMT16的DE-EN部分数据集Multi-30K上,困惑度(交叉熵损失)而言,基于RNN的Bahdanau Attention的性能最差。不仅在验证集上的最佳性能远差于另外两个模型,而且在6个epoch后就开始过拟合了。在这项数据集上,显然基于卷积的attention性能最佳,但是有可能是数据集不够大的原因,Transformer并没有能超越CNN based attention。在2017年的Attention is All You Need论文中,在机器翻译的BLEU指标上,Transformer的基准模型在EN-DE的WMT14数据上击败了Conv based attention模型。
基于RNN的attention迅速过拟合的原因或许还是与RNN的隐向量训练有关,如果将词向量的编码换成相似的双向语言模型Elmo或许会有所提升,但是基于双向的语言模型终究似乎没办法更加具有长程的关注信息,如果只是添加attention似乎也只是一种不触及本质的提升。CNN的词+位置编码能捕获词语的上下文,但是由于CNN的窗口固定,所以在本质上也只是结合一个词语的周遭固定窗口的上下文的一种词嵌入。不过相对于简单的基于RNN的attention,个人猜想由于在低细粒度的层次捕获了足够的信息,如卷积核为3就是捕获了三个词一组的信息,与日常的短语级别的长度相似。然后再关注这些短语级别的注意力,这样便在两个细粒度上获取了信息。但是self-attention则是更进一层的在自己本身的词嵌入中融入了词的上下文信息,进而很可能隐式地表达出了某种深层次的语言信息如语义、指代等等,因此也有了2018年的BERT等基于Transformer的大规模预训练语言模型的发展。因为只要改变训练的目标与损失函数就能无监督地获得词嵌入的更好表示,而获取了这些隐藏信息后再使用其他模型进行相关解码,直接应用于下游领域甚至都能直接获得相当强的性能,似乎说明某些语言学的信息也能被隐式地表达与分布式的词嵌入空间当中。
