指代消解的步骤
指代消解任务可以分为两步式的任务:
- 检测Mention的边界
- 对于Mention进行聚类
对于第一个任务,举个例子:
“I voted for Nader because he was most aligned with my values,” she said
在这一句中,如果只是做mention检测的任务的话我们得到的结果应该是:
“[I] voted for [Nader] because [he] was most aligned with [ [my] values],” [she] said
在这里所有的mention都被识别了,其中my values这个实体还存在嵌套的现象,即my指代的是之前的I。
但是一个完整的指代消解系统接下开还需要做的就是分类这些Mention,如果将之视为一个聚类问题的话,显然地,可以将指代相同实体的Mention聚类到一起。
对于指代消解任务而言,对于Mention的聚类比实体识别(即边界检测)任务要难多了。
边界检测
对于边界检测而言,我们又可以从Mention的种类出发进行任务的分解:
| 种类 | Pronoun | Named Entity | Noun Phase |
|---|---|---|---|
| 举例 | I, she, he, you… | People, Places, Orgnazations… | “a dog” |
| 对应NLP任务 | POS tagger | NER | Constitutency Parser |
在进行这些任务的时候,我们又会遇到一些特例:
It is sunny.
Every Student
No Student
500 miles
上面的这些特例里,有it这种特殊的指代方式,如代指心情,天气等等。还有every, no等绝对意义的名词短语,很显然every student不是一个具体的实体的一种指代。当然对于500 miles这种表示数量的名词短语也不会是指代。
那么我们就有两种策略:
- 第一种就是先构造一个classifier,将所有的mention candidates筛查一遍,去除其中的特例。
- 第二种自然就是将所有可能的mention全都保留。
然后如果我们考虑第二种策略的话,从更加宏观的角度来看,我们又应该如何选择mention detection的策略呢。简单的想自然就是将上述三种NLP任务对应的模型组合起来就好了,但是在后面我们还能做到真正的端到端coref,即不单独对于某个部分设计模型。
语言学知识的补充
在coref resolution中,我们经常会考虑两种语言现象,共指和指代。
对于指代而言,我们更常见的是anaphora。
anaphora & coreference
举个例子:
对于以下的句子:
Barack Obama said he would sign the bill, Barack was …
那么coref和anaphora的对比图如下:
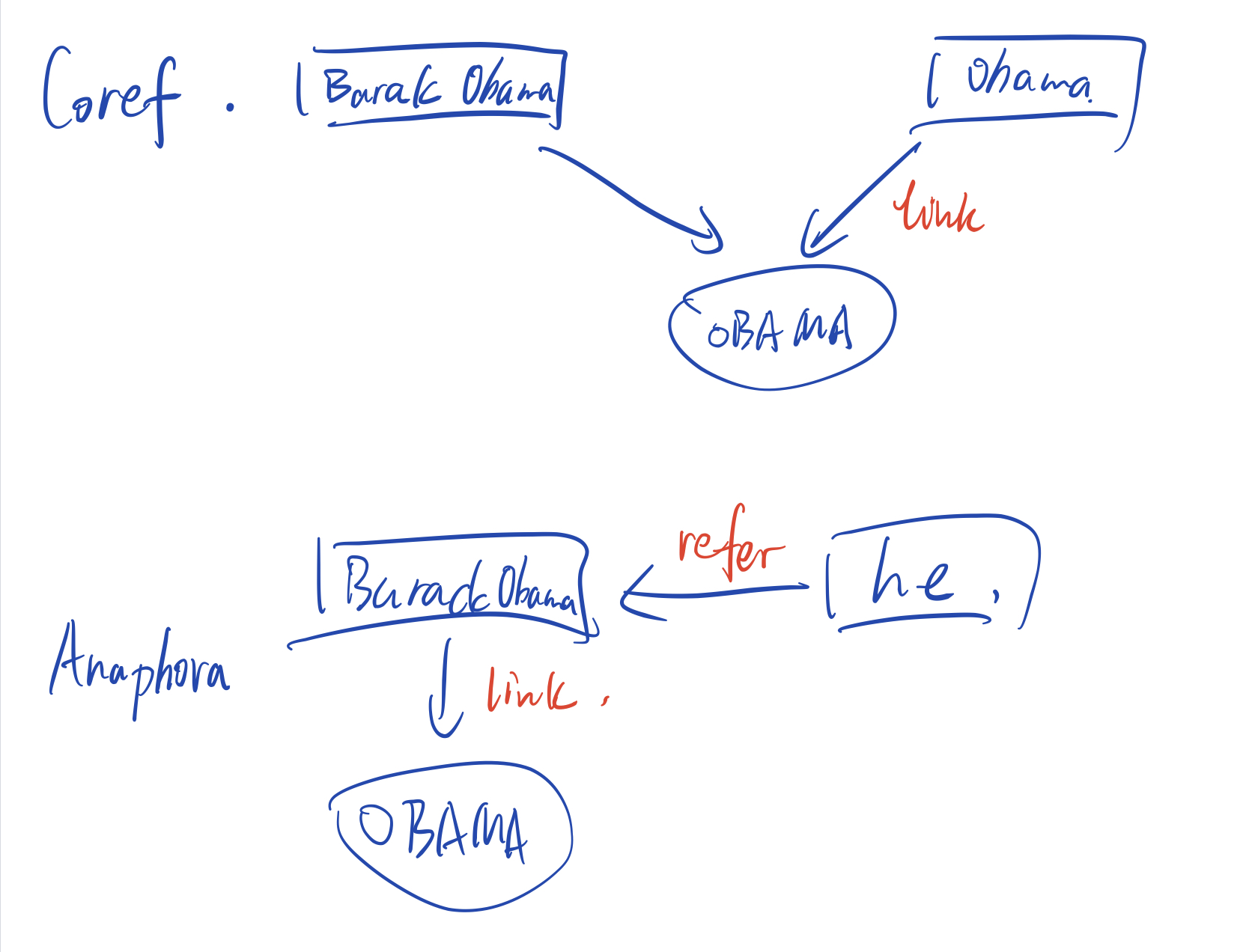
上图展示了coref和anaphora的区别,其中OBAMA表示的是现实世界的前美国总统巴拉克奥巴马,在coref中,就是后半句的Obama和句子开始位置的Barack Obama同时指向了现实世界的实体奥巴马,而anaphora则是前半句中的he指代的就是前面出现的Barack Obama这一Mention,而Barack Obama则会产生一个实体link到实体奥巴马中。
cataphora
cataphora可以看作为anaphora的逆操作,因为一般情况下,我们都是使用代词来指代前面的某个具体的mention,然而反方向的指代在语言中也是存在的。
如: 奥斯卡王尔德的《道雷格林的画像》选段
“$From$ the corner of the divan of Persian saddle-bags on which he was lying, smoking, as was his custom, innumerable cigarettes, Lord Henry Wotton could just catch the gleam of the honey-sweet and honey-coloured blossoms of a laburnum, whose tremulous branches seemed hardly able to bear the burden of a beauty so flamelike as theirs; and now and then the fantastic shadows of birds in flight flitted across the long tussore-silk curtains that were stretched in front of the huge window, producing a kind of momentary Japanese effect, and making him think of those pallid, jade-faced painters of Tokyo who, through the medium of an art that is necessarily immobile, seek to convey the sense of swiftness and motion. “

在上面的选段里,“Lord Henry Wotton”才是前句中的he以及his的指代。
anaphora的特例
对于我们要做的有意义的coref resolution而言,有些anaphora其实也不应该被算入最后的结果。
No dancer twisted her knee.
对于her而言,很显然这个词指代的是“no dancer”,然而对于现实任务而言这显然是毫无意义的,因为no dancer并不能够对应现实世界的一个实体。
如果将coref和anaphora两个集合画出文恩图的话,coref和anaphora的交集是pronominal anaphora,而anaphora的剩下的集合就是bridging anaphora。
举个例子:
We went to see a movie yesterday.
The tickets were expensive.
在上面的两句话中, the tickets指代的就是上一句的a movie,但是这两个mention之间却并没有一个coref的关系。
模型种类
总结下来有四种实现coreference resolution的方案:
- rule-based 如:Hobbs naive algorithm
- 基于Mention Pair
- 基于Mention Ranking
- 聚类
评价指标
$B^3$ eval metric
将结果看为一种聚类的话,对于预测出来的一种聚类集合,可以计算其准确率和召回率。
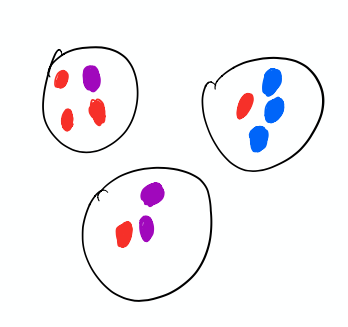
如图所示,对于标红的mention而言,加入左上方的聚类是红色mention的正确集合,那么$precision = \frac{3}{3+1}$,而$recall = \frac{3}{3+1+1}$。
End2End Neural Coreference Resolution
任务建模
将端到端的coref resolution看作为对所有可能的span的一组决策。输入就是一篇文档$D$,包括了$T$个单词。所以对于文档,我们就会有$\frac{T(T+1)}{2}$个可能的span。然后将文档$D$中的$span_i$由$START(i)$和$END(i)$表示。然后对于拥有相同$START$的span,我们将至用$END(i)$来排序。
那么任务可以这样表达:对于每一个$span_i$来说,我们找到其antecedent $y_i$ 。而$y_i$的antecedent可能的结果的集合可以表示为$\mathcal{y(i)}= {\epsilon,1,…,i-1},也就是其他所有的位置靠前的span以及不存在antecedent的情况。对于$\epsilon$而言,可能有两种情况。首先就是这个span本身就不是一个entity mention,或者就是这个span虽然是entity mention,但是与先前的任何一个span都没有coref关系。
模型
这个模型的建模的分布应该是:
其中$s(i,j)$就是$span_i$与$span_j$之间的coref分数。
对于这个pairwise的分数而言,我们需要考虑三个要素:
- $span_i$是否是一个mention
- $span_j$是否是一个mention
- $span_j$是否是$span_i$的一个antecedent
故,这里的$s_m(i)$是$span_i$的mention得分,$s_a(i,j)$是$span_j$是$span_i$的antecedent的得分。
score函数网络
在这里,$\mathbf{g_i}$表示的是$span_i$的embedding,而$\mathbf{g_i} \circ \mathbf{g_j}$则是这两个$span$的逐元素积,$\phi(i,j)$则是一个特征向量,编码了作者和主题信息以及两个$span$之间的距离信息。
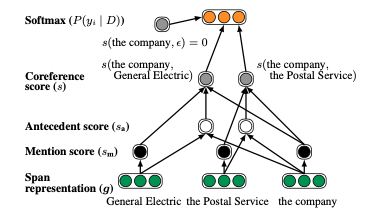
span的表示
备注:2019年的SpanBERT模型对于该部分进行了改进。
对于预测coref关系而言两种类型的信息很重要:
- mention span的上下文信息
- 其内部的结构
建模方案:使用双向LSTM网络编码span内外的信息,同时加上attention机制。
一个单词的词表示:$x_t^{\ast}$就是将这个lstm对应的$t$位置的前后两个方向的tensor输出拼接起来即可。
至于attention层:
第一个公式:查询$x_t^{\ast}$的attention得分,然后再将所有span内时刻的向量的attention得分softMax归一化,最后重组出新的$x_i$,作为这个span的加权平均化的向量表示。
最后我们将一个span的首尾词向量,span的加权词向量还有span的特征向量拼接起来作为这个span最后的表示:
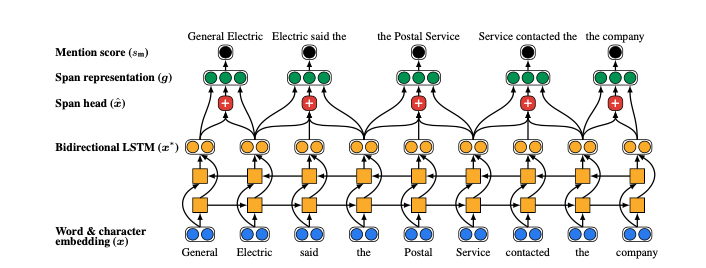
Inference & Learning
如果枚举整个模型的话,对于长度为$T$的文本,其复杂度是$O(T^4)$。所以需要在训练和验证时进行剪枝。
- 首先是只考虑最多$L$个词计算mention score。
- 其次就是减少span个数了,取一个超参数$\lambda$,只保留$\lambda T$个拥有最高的mention score的span,并且对于每个span,我们只考虑最多$K$个antecedent。
- 最后,对于交叉的span,使用如下方法。按照mention score降序排列一个个选择,除非对于一个$span_i$,已经存在一个被选出的$span_j$,使得$START(i) < START(j) \le END(i) END(j) \vee START(j) < START(i) \le END(j) < END(i)$,也就是有交叉。
学习的目标函数就是这个对数似然: 其中$GOLD(i)$就是$span_i$的gold cluster集合。特别的,如果$span_i$不属于任何cluster,或者所有的gold antecedent都被剪枝掉了,那么$GOLD(i) = {\epsilon}$。
这样的话可以使得一开始随机的剪枝得到误差传递,这样模型也就学着合理剪枝,比如$s_m$值是被考虑的。同时之前的将$\epsilon$的mention score归零也确保了只会将非正确的antecedent的分数降低,不会将$\epsilon$的得分升高。
实验细节
词表示
使用的是固定三百维和五十维的GloVe。而OOV词汇则是用charCNN编码。卷积层的window size有3,4,5,每个都有50个filter。
隐藏层
200维度隐藏层的LSTM。每个前馈网络的维度是两个150的线性层。
特征向量
将speaker的信息直接二进制位编码,即只有两种情况,$span_i$和$span_j$同属一个speaker,或不同。然后位置信息就直接使用Clark和Manning在2016年使用的方式,考虑向量$[1,2,3,4,5-7,8-15,16-31,32-63,64+]$,这样把speaker,genre,span间距以及mention长度编码为20维的向量。
